Otwieranie czarnej skrzynki, czyli wytłumaczalna sztuczna inteligencja
Podczas wizyty w szpitalu modele sztucznej inteligencji (AI) mogą pomagać lekarzom , analizując obrazy medyczne lub przewidując wyniki leczenia pacjentów na podstawie danych historycznych . Jeśli ubiegasz się o pracę , algorytmy AI mogą być używane do przeglądania życiorysów, klasyfikowania kandydatów do pracy, a nawet przeprowadzania wstępnych rozmów kwalifikacyjnych. Gdy chcesz obejrzeć film na Netfliksie, algorytm rekomendacji przewiduje, które filmy prawdopodobnie Ci się spodobają, na podstawie Twoich nawyków oglądania. Nawet gdy prowadzisz samochód, algorytmy predykcyjne działają w aplikacjach nawigacyjnych, takich jak Waze i Mapy Google, optymalizując trasy i przewidując wzorce ruchu, aby zapewnić szybszą podróż.
W miejscu pracy narzędzia oparte na sztucznej inteligencji, takie jak ChatGPT i GitHub Copilot, są wykorzystywane do tworzenia wiadomości e-mail, pisania kodu i automatyzowania powtarzających się zadań. Badania wskazują, że do 2030 roku sztuczna inteligencja może zautomatyzować aż 30% godzin pracy .
Ale powszechnym problemem tych systemów AI jest to, że ich wewnętrzne działanie jest często skomplikowane do zrozumienia – nie tylko dla ogółu społeczeństwa, ale także dla ekspertów! Ogranicza to sposób, w jaki możemy używać narzędzi AI w praktyce. Aby rozwiązać ten problem i dostosować się do rosnących wymagań regulacyjnych, wyłonił się obszar badań znany jako „wytłumaczalna AI”.
Sztuczna inteligencja i uczenie maszynowe: co kryje się w tej nazwie?
Biorąc pod uwagę obecny trend w kierunku integracji sztucznej inteligencji z organizacjami i powszechną mediatyzację jej potencjału, łatwo jest się pogubić, zwłaszcza że istnieje tak wiele terminów określających systemy sztucznej inteligencji, w tym uczenie maszynowe, głębokie uczenie i duże modele językowe, aby wymienić tylko kilka.
Mówiąc najprościej, AI odnosi się do rozwoju systemów komputerowych, które wykonują zadania wymagające ludzkiej inteligencji, takie jak rozwiązywanie problemów, podejmowanie decyzji i rozumienie języka . Obejmuje różne poddziedziny, takie jak robotyka, widzenie komputerowe i rozumienie języka naturalnego.
Jednym z ważnych podzbiorów AI jest uczenie maszynowe , które umożliwia komputerom uczenie się na podstawie danych zamiast bycia wyraźnie zaprogramowanym do każdego zadania. Zasadniczo maszyna analizuje wzorce w danych i wykorzystuje te wzorce do formułowania przewidywań lub podejmowania decyzji. Na przykład pomyśl o filtrze spamu e-mail. System jest szkolony na tysiącach przykładów zarówno spamu, jak i nie-spamu. Z czasem uczy się wzorców, takich jak określone słowa, frazy lub dane nadawcy, które są powszechne w spamie.
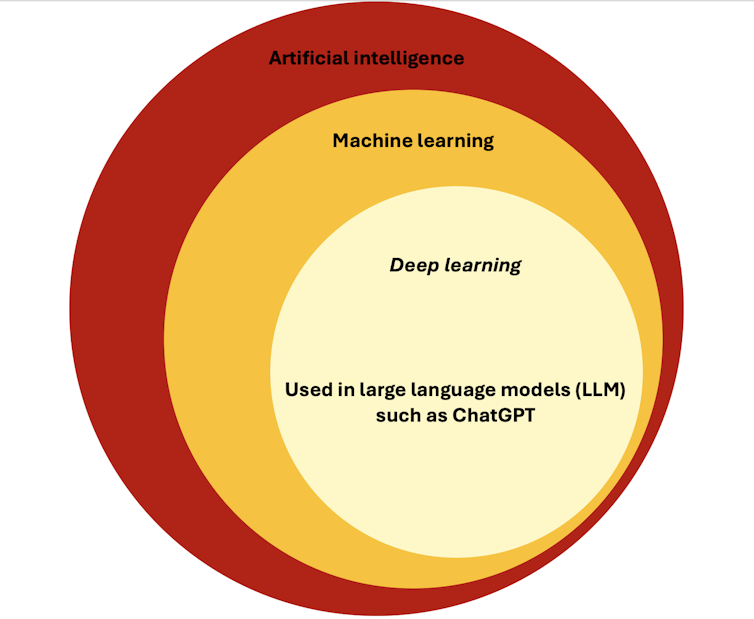
Głębokie uczenie się , kolejny podzbiór uczenia maszynowego, wykorzystuje złożone sieci neuronowe z wieloma warstwami, aby uczyć się jeszcze bardziej wyrafinowanych wzorców. Udowodniono, że głębokie uczenie się ma wyjątkową wartość podczas pracy z danymi obrazowymi lub tekstowymi i jest podstawową technologią leżącą u podstaw różnych narzędzi do rozpoznawania obrazów lub dużych modeli językowych, takich jak ChatGPT.
Regulacja sztucznej inteligencji
Powyższe przykłady pokazują szerokie zastosowanie AI w różnych branżach. Kilka z tych scenariuszy, takich jak sugerowanie filmów na Netflixie, wydaje się stosunkowo mało ryzykownych. Jednak inne, takie jak rekrutacja, ocena zdolności kredytowej lub diagnoza medyczna, mogą mieć duży wpływ na czyjeś życie, co sprawia, że kluczowe jest, aby miały miejsce w sposób zgodny z naszymi celami etycznymi.
Uznając to, Unia Europejska zaproponowała ustawę o AI , którą jej parlament zatwierdził w marcu. Te ramy regulacyjne klasyfikują zastosowania AI na cztery różne poziomy ryzyka: niedopuszczalne, wysokie, ograniczone i minimalne, w zależności od ich potencjalnego wpływu na społeczeństwo i jednostki. Każdy poziom podlega różnym stopniom regulacji i wymagań.
Niedopuszczalne ryzyko Systemy sztucznej inteligencji, takie jak systemy wykorzystywane do punktacji społecznej lub predykcyjnego działania policji, są zakazane w UE, ponieważ stanowią poważne zagrożenie dla praw człowieka.
Dozwolone są systemy sztucznej inteligencji obarczone wysokim ryzykiem, jednak podlegają one najsurowszym regulacjom, ponieważ w razie awarii lub niewłaściwego użycia mogą spowodować poważne szkody, m.in. w egzekwowaniu prawa, rekrutacji i edukacji.
Ograniczone ryzyko Systemy AI, takie jak chatboty lub systemy rozpoznawania emocji, niosą ze sobą pewne ryzyko manipulacji lub oszustwa. Ważne jest, aby ludzie byli informowani o swojej interakcji z systemem AI.
Do systemów AI o minimalnym ryzyku zaliczają się wszystkie inne systemy AI, takie jak filtry spamu, które można wdrażać bez dodatkowych ograniczeń.
Potrzeba możliwości wyjaśnienia
Wielu konsumentów nie chce już akceptować, że firmy obwiniają ich decyzje o algorytmy typu black-box. Weźmy na przykład incydent z Apple Card , w którym mężczyźnie przyznano znacznie wyższy limit kredytowy niż jego żonie, pomimo wspólnych aktywów. Wywołało to publiczne oburzenie, ponieważ Apple nie było w stanie wyjaśnić powodów decyzji swojego algorytmu. Ten przykład podkreśla rosnącą potrzebę wyjaśnialności decyzji podejmowanych przez sztuczną inteligencję, nie tylko po to, aby zapewnić zadowolenie klienta, ale także po to, aby zapobiec negatywnemu postrzeganiu przez opinię publiczną.
W przypadku systemów AI obarczonych wysokim ryzykiem artykuł 86 ustawy o AI ustanawia prawo do żądania wyjaśnień dotyczących decyzji podejmowanych przez systemy AI, co stanowi istotny krok w kierunku zapewnienia przejrzystości algorytmów.
Jednak oprócz zgodności z przepisami prawa, przejrzyste systemy sztucznej inteligencji oferują szereg innych korzyści zarówno właścicielom modeli, jak i osobom, na które wpływają decyzje podejmowane przez systemy.
Przejrzysta sztuczna inteligencja
Po pierwsze, przejrzystość buduje zaufanie: gdy użytkownicy rozumieją, jak działa system AI, chętniej z nim współpracują . Po drugie, może zapobiegać stronniczym wynikom , umożliwiając regulatorom sprawdzenie, czy model niesprawiedliwie faworyzuje określone grupy. Wreszcie, przejrzystość umożliwia ciągłe doskonalenie systemów AI poprzez ujawnianie błędów lub nieoczekiwanych wzorców .
Ale w jaki sposób możemy osiągnąć przejrzystość w dziedzinie sztucznej inteligencji?
Ogólnie rzecz biorąc, istnieją dwa główne podejścia do zwiększania przejrzystości modeli sztucznej inteligencji .
Po pierwsze, można użyć prostych modeli, takich jak drzewa decyzyjne lub modele liniowe, aby dokonać prognoz . Te modele są łatwe do zrozumienia, ponieważ ich proces podejmowania decyzji jest prosty. Na przykład, model regresji liniowej można wykorzystać do przewidywania cen domów na podstawie cech, takich jak liczba sypialni, metraż i lokalizacja. Prostota polega na tym, że każdej cesze przypisana jest waga, a prognoza jest po prostu sumą tych ważonych cech. Oznacza to, że można wyraźnie zobaczyć, w jaki sposób każda cecha przyczynia się do ostatecznej prognozy ceny domu.
Jednak w miarę jak dane stają się coraz bardziej złożone, te proste modele mogą przestać być wystarczająco skuteczne .
Dlatego deweloperzy często zwracają się ku bardziej zaawansowanym „modelom czarnej skrzynki”, takim jak głębokie sieci neuronowe, które mogą obsługiwać większe i bardziej złożone dane, ale są trudne do zinterpretowania. Na przykład głęboka sieć neuronowa z milionami parametrów może osiągnąć bardzo wysoką wydajność, ale sposób, w jaki podejmuje decyzje, jest niezrozumiały dla ludzi, ponieważ jej proces decyzyjny jest zbyt duży i złożony.
Wyjaśnialna sztuczna inteligencja
Inną opcją jest użycie tych potężnych modeli black-box wraz z oddzielnym algorytmem wyjaśniającym w celu wyjaśnienia modelu lub jego decyzji . To podejście, znane jako „wyjaśnialna sztuczna inteligencja”, pozwala nam korzystać z mocy złożonych modeli, jednocześnie oferując pewien poziom przejrzystości.
Jedną z dobrze znanych metod jest wyjaśnienie kontrfaktyczne . Wyjaśnienie kontrfaktyczne wyjaśnia decyzję modelu poprzez identyfikację minimalnych zmian w cechach wejściowych, które doprowadziłyby do innej decyzji.
Na przykład, jeśli system AI odmawia komuś pożyczki, kontrfaktyczne wyjaśnienie może poinformować wnioskodawcę: „ Gdyby twój dochód był o 5000 USD wyższy, twoja pożyczka zostałaby zatwierdzona ”. Dzięki temu decyzja staje się bardziej zrozumiała, podczas gdy zastosowany model uczenia maszynowego nadal może być bardzo złożony. Jednak jedną wadą jest to, że te wyjaśnienia są przybliżeniami, co oznacza, że może być wiele sposobów wyjaśnienia tej samej decyzji.
Droga przed nami
W miarę jak modele AI stają się coraz bardziej złożone, ich potencjał transformacyjnego wpływu rośnie – ale tak samo jak ich zdolność do popełniania błędów. Aby AI była naprawdę skuteczna i godna zaufania, użytkownicy muszą zrozumieć, w jaki sposób te modele podejmują decyzje.
Przejrzystość to nie tylko kwestia budowania zaufania, ale także kluczowa dla wykrywania błędów i zapewniania uczciwości. Na przykład w przypadku samochodów autonomicznych, wytłumaczalna sztuczna inteligencja może pomóc inżynierom zrozumieć, dlaczego samochód błędnie zinterpretował znak stop lub nie rozpoznał pieszego . Podobnie, w przypadku rekrutacji, zrozumienie, w jaki sposób system sztucznej inteligencji klasyfikuje kandydatów do pracy, może pomóc pracodawcom uniknąć stronniczych wyborów i promować różnorodność .
Koncentrując się na przejrzystych i etycznych systemach sztucznej inteligencji, możemy zagwarantować, że technologia będzie służyć zarówno jednostkom, jak i społeczeństwu w sposób pozytywny i sprawiedliwy.
David Martens, profesor odpowiedzialnej sztucznej inteligencji na Uniwersytecie w Antwerpii
stypendysta podoktorancki, Uniwersytet w Antwerpii
Artkuł The Convesation udostępniony na licencji CC. Oryginał jest TUTAJ